


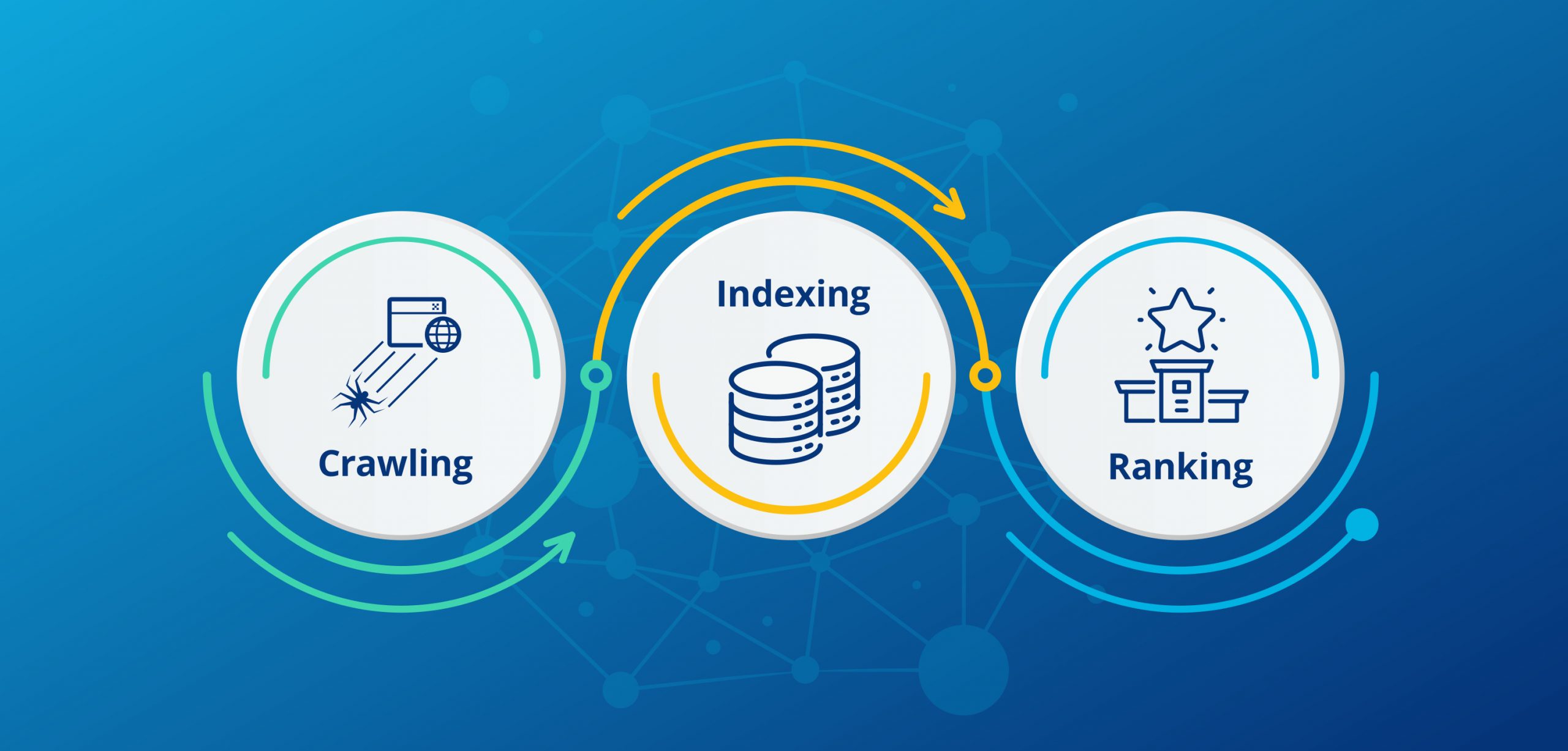
Crawling and indexing are two interdependent processes that work together to help search engines understand and rank websites. Crawling is the process of discovering and scanning websites for content, while indexing is the process of storing and organizing that content in a massive database. When a website is crawled, its content is extracted and added to the index, where it can be quickly retrieved and displayed in response to user queries. In other words, crawling provides the raw material for indexing, and indexing provides the framework for organizing and retrieving that material. By understanding how crawling and indexing work together, website owners can optimize their website’s structure, content, and meta tags to improve their search engine rankings and online visibility.You can add this paragraph to the end of the article, or integrate it into the existing content. Here’s an updated version of the article with the additional paragraph:
In the world of search engine optimization (SEO), crawling and indexing are two fundamental concepts that play a crucial role in determining the visibility and ranking of a website. While often used interchangeably, crawling and indexing are distinct processes that serve different purposes. In this article, we’ll delve into the definitions, processes, and importance of crawling and indexing, as well as their applications in SEO, Python, and database management.
Crawling: The First Step in the SEO Journey
Crawling, also known as spidering or web scraping, is the process by which search engines like Google, Bing, and Yahoo discover and scan websites for content. This process involves a software program, known as a crawler or spider, that systematically navigates the web, following hyperlinks from one page to another. The crawler’s primary function is to identify and gather data about the website’s structure, content, and keywords.
Crawling Definition
Crawling is the automated process of scanning and gathering data from websites, which is then used to create a massive database of web pages. This database is the foundation of search engine results pages (SERPs), allowing users to find relevant information online.
Crawling in SEO
In the context of SEO, crawling is crucial for website owners and digital marketers. By understanding how search engines crawl websites, you can optimize your online presence to improve visibility, drive more traffic, and increase conversions. Here are some actionable tips to improve your website’s crawling:
- Optimize your website’s structure: Ensure that your website has a clear, hierarchical structure, making it easy for crawlers to navigate and gather data.
- Use descriptive and keyword-rich titles: Craft titles that accurately describe your content and include relevant keywords, helping crawlers understand the context and relevance of your pages.
- Internal linking: Use internal linking to help crawlers navigate your website and discover new content.
- Regularly update your content: Fresh, high-quality content encourages crawlers to return to your website more frequently, improving your chances of ranking higher in search engine results.
Indexing: The Key to Search Engine Visibility
Indexing is the process by which search engines organize and store data gathered during the crawling process. This data is then used to create a massive database of web pages, which is queried when a user submits a search query. Indexing is a critical step in the SEO journey, as it determines the visibility and ranking of your website in search engine results.
Indexing Meaning
Indexing refers to the process of organizing and storing data in a database, making it easily accessible and queryable. In the context of search engines, indexing is the process of creating a massive database of web pages, which is used to generate search engine results.
- Content Storage: The crawled content is stored in a massive database, which is typically distributed across multiple servers.
- Content Organization: The content is organized using various algorithms and data structures, such as inverted indexes and hash tables.
- Query Processing: When a user submits a query, the search engine’s algorithm searches the index to retrieve relevant content.
Indexing in Python
In Python, indexing is used to optimize the performance of databases and data structures. For example, the pandas library uses indexing to optimize data retrieval and manipulation. In Python, indexing can be achieved using various data structures, such as:
- Lists: Lists can be indexed using integers or slices.
- Dictionaries: Dictionaries can be indexed using keys.
- DataFrames: DataFrames can be indexed using labels or integers.
Indexing on Database
Indexing is also used in database management to optimize query performance. In a database, indexing involves creating a data structure that allows for efficient retrieval of data. Common indexing techniques include:
- B-Tree Indexing: A self-balancing search tree that allows for efficient insertion, deletion, and search operations.
- Hash Indexing: A data structure that uses hash functions to map keys to values.
- Full-Text Indexing: A data structure that allows for efficient retrieval of text data.
Indexing Google
Google uses a complex indexing algorithm to organize and retrieve content from its massive database. Google’s indexing algorithm involves the following steps:
- Crawling: Google’s crawlers discover and scan websites for content.
- Content Analysis: Google’s algorithm analyzes the content to identify keywords, meta tags, and other relevant information.
- Indexing: The content is stored and organized in Google’s massive database.
Indexing Google Sites
Google Sites is a website builder that allows users to create and host websites. To optimize indexing on Google Sites, users can:
- Use Descriptive Titles: Use descriptive and keyword-rich titles to help Google’s algorithm understand the content.
- Use Meta Tags: Use meta tags to provide additional information about the content.
- Use Header Tags: Use header tags to structure the content and highlight key points.
Indexing Keywords
Indexing keywords is the process of identifying and organizing keywords that are relevant to a website’s content. To optimize indexing keywords, website owners can:
- Use Keyword Research Tools: Use tools like Google Keyword Planner or Ahrefs to identify relevant keywords.
- Use Keyword-Rich Content: Use keyword-rich content to help Google’s algorithm understand the website’s relevance.
- Use Meta Tags: Use meta tags to provide additional information about the keywords.
Crawling and Indexing: A Symbiotic Relationship
Crawling and indexing are two interdependent processes that work together to help search engines understand and rank websites. Crawling is the process of discovering and scanning websites for content, while indexing is the process of storing and organizing that content in a massive database. When a website is crawled, its content is extracted and added to the index, where it can be quickly retrieved and displayed in response to user queries. In other words, crawling provides the raw material for indexing, and indexing provides the framework for organizing and retrieving that material. By understanding how crawling and indexing work together, website owners can optimize their website’s structure, content, and meta tags to improve their search engine rankings and online visibility.
Conclusion
In conclusion, crawling and indexing are two fundamental concepts in SEO, which are critical for website owners and digital marketers. By understanding how search engines crawl and index websites, you can optimize your online presence to improve visibility, drive more traffic, and increase conversions. Remember to optimize your website’s structure, content, and keywords to encourage crawlers to return more frequently, and improve your chances of ranking higher in search engine results.
Pretty nice post. I just discovered your weblog and wanted to say
that I’ve really enjoyed surfing around your blog posts.
In any full case
I’ll be subscribing to your feed (hopefully I could think it is)
and I hope
you write again soon!